A lot of programmers believe that compilers are magic black boxes in which you put your messy code in and get a nice optimized binary out. The hallway philosophers will often start a debate on which language features or compiler flags to use in order to capture the full power of the compiler’s magic. If you have ever seen the GCC codebase, you would really believe it must be doing some magical optimizations coming from another planet.
Nevertheless, if you analyze the compiler’s output you will found out that the compilers are not really that great at optimizing your code. Not because people writing them wouldn’t know how to generate efficient instructions, but simply because the compilers can only reason about a very small part of the problem space 1.
In order to understand why magic compiler optimizations are not going to speed up your software, we have to go back in time when the dinosaurs roamed the earth and the processors were still extremely slow. The following graph shows the relative processor and memory performance improvements throughout the years (1980-2010), taken from 2:
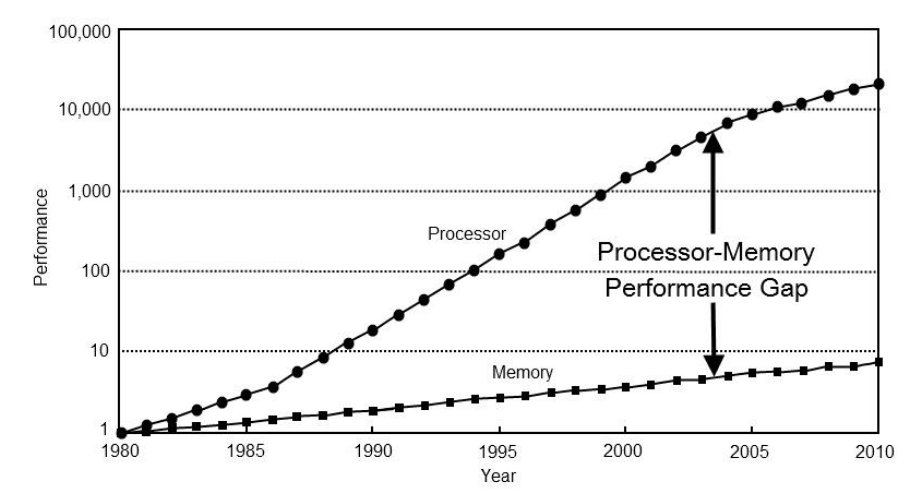
The problem that this picture represents is that the CPU performance has improved tremendously over the years (y axis is in a logarithmic scale), while the memory performance increased at a much slower pace:
- In 1980 the RAM latency was ~1 CPU cycle
- In 2010 the RAM latency was ~400 CPU cycles
So, what? We spend a few more cycles when loading something from the memory, but the computers are still way faster than they used to be. Who cares how many cycles we spend?
Well, for one it’s sad to know that even if we get better compilers or faster hardware, the speed of our software is not going to drastically improve, since they are not the reason why our software is slow. The main problem that we have today lies in utilizing the CPUs to their full potential.
The following table displays the latency numbers of common operations, taken from 3. Scaled latency column represents latency in numbers that are easier to understand for humans.
| Event | Latency | Scaled Latency |
|---|---|---|
| 1 CPU cycle | 0.3 ns | 1 s |
| L1 cache access | 0.9 ns | 3 s |
| L2 cache access | 3 ns | 10 s |
| L3 cache access | 10 ns | 33 s |
| Main memory access | 100 ns | 6 min |
| Solid-state disk I/O | 10-100 µs | 9-90 hours |
| Rotation disk I/O | 1-10 ms | 1-12 months |
When looking at the scaled latency column we can quickly figure out that accessing memory is not free and for the vast majority of applications the CPU is twiddling its thumbs while waiting for the memory to arrive 4. The reasons for that are two-fold:
The programming languages, which we are still using today, were made in time when the processors were slow and the memory access latency wasn’t much of a problem.
The industry best practices are still revolving around the object oriented programming which does not perform well on a modern hardware.
Programming languages
| Language | Invented in |
|---|---|
| C | 1975 |
| C++ | 1985 |
| Python | 1989 |
| Java | 1995 |
| Javascript | 1995 |
| Ruby | 1995 |
| C# | 2002 |
The programming languages listed above are all over 20 years old and their initial design decisions, like Python’s global interpreter lock or Java’s everything is an object mindset, no longer make any sense today. The hardware has changed tremendously with the addition of the CPU caches and multiple cores, while the programming languages are still based on the ideas that are no longer true.
Most of the modern programming languages are trying to make your life easier by taking away the sorrows of manual memory management. While not having to think about the memory is going to make you more productive, that productivity comes at a heavy price.
Allocating chunks of memory without oversight is going to make your program slow, mostly due to random memory accesses (cache misses) that will cost you a few hundred CPU cycles each. Nevertheless, most programming languages listed above still act like the random memory allocation is not a big deal and you shouldn’t worry about it because the computers are so fast.
Yes, the computers are extremely fast, but only if you write your software in a way that plays nice with your hardware. On the same hardware you can experience a buttery smooth 3D game and a visibly lagging MS Word. Obviously, the hardware is not the issue here and we can squeeze much more out of it than an average application does.
The hardware has improved, but the languages didn’t
Another problem with the current programming languages is that they didn’t evolve beyond the C-style type of programming. Not that there is anything wrong with writing for loops, but it’s getting harder and harder to exploit our CPUs to their full potential while still managing the complexity of the modern programs.
In some way, they lack the functionality that would allow you to program in a way that is convenient for humans, while still leveraging the hardware to achieve the best possible performance. While the sorts of abstractions that we are using today are convenient, they tend to not perform well on a modern hardware.
This is going to be a long winded explanation, but let’s start with an example:
Imagine we are simulating an ant colony. The colony’s administration department was destroyed in the latest anteater attack, thus they no longer know how many warrior ants are still living in the colony.
Help our ant The Administrator count the warrior ants!
Here is an example of how the majority of programmers, including myself, would write the code for solving this problem. It’s written in a typical Object Oriented Enterprise Cache Trasher way, pardon my Java:
class Ant {
public String name = "unknownAnt";
public String color = "red";
public boolean isWarrior = false;
public int age = 0;
}
// shh, it's a tiny ant colony
List<Ant> antColony = new ArrayList<>(100);
// fill the colony with ants
// count the warrior ants
long numOfWarriors = 0;
for (Ant ant : antColony) {
if (ant.isWarrior) {
numOfWarriors++;
}
}
The solution above is short and easy to understand. Unfortunately it doesn’t perform well on a modern hardware.
Every time you request a byte of memory that is not already present in one of the CPU caches, an entire cache line is fetched from the main memory even if you need only 1 byte. Since fetching the data from the main memory is quite expensive (see the latency table above), we would prefer to keep the number of memory fetches as small as possible. This could be achieved in two ways:
- By reducing the amount of data that has to be fetched for our task.
- By keeping the necessary data in contiguous blocks in order to fully utilize the cache lines.
For the example above, we can reason about the data that is being fetched as (I am assuming compressed oops are being used, please correct me if I am wrong):
+ 4 bytes for the name reference
+ 4 bytes for the color reference
+ 1 byte for the warrior flag
+ 3 bytes for padding
+ 4 bytes for the age integer
+ 8 bytes for the class headers
---------------------------------
24 bytes per ant instance
How many times do we have to touch the main memory in order to count all the warrior ants (assuming the ant colony data is not already loaded in the cache)?
If we take in consideration that on a modern CPU the cache line size is 64 bytes, that means we can fetch at most 2.6 ant instances per cache line. Since this example is written in Java, where everything is an object that lives somewhere in the heap, we know that the ant instances might live on a different cache lines 5.
In the worst case scenario, the ant instances are not allocated one after another and we can fetch only one instance per cache line. For the entire ant colony that means we have to touch the main memory 100 times and for every cache line fetched (64 bytes), we are only using 1 byte. In other words, we are throwing away 98% of the fetched data. This is a pretty inefficient approach for counting our ants.
Speedup
Can we rewrite our program in a way that would be more prudent with fetching the memory and thus improve the performance of our program? Yes, we can.
We are going to use the most naive data oriented approach. Instead of modelling ants one by one, we model the entire colony at once:
class AntColony {
public int size = 0;
public String[] names = new String[100];
public String[] colors = new String[100];
public int[] ages = new int[100];
public boolean[] warriors = new boolean[100];
// I am aware of the fact that this array could be removed
// by splitting the colony in two (warriors, non warriors),
// but that is not the point of this story.
//
// Yes, you can also sort it and enjoy in an additional
// speedup due to branch predictions.
}
AntColony antColony_do = new AntColony();
// fill the colony with ants and update size counter
// count the warrior ants
long numOfWarriors = 0;
for (int i = 0; i < antColony_do.size; i++) {
boolean isWarrior = antColony_do.warriors[i];
if (isWarrior) {
numOfWarriors++;
}
}
The two presented examples are algorithmically equivalent (O(n)), but the data oriented solution outperforms the object oriented one. Why?
It’s because the data oriented example fetches less data and that data is fetched in contiguous chunks - we fetch 64 warrior flags at once and there is no waste. Since we are only fetching the data that we need, we only have to touch the main memory twice instead of once for every ant (100 times). This is a way more efficient approach for counting our warrior ants.
I made some performance benchmarks with the Java Microbenchmark Harness (JMH) toolkit and the results are shown in the table below (measured on Intel i7-7700HQ @3.80GHz). I ignored the confidence intervals in order to keep the table clean, but you can run your own benchmarks by downloading and running the benchmark code.
| Task (colony size) | Object Oriented | Data Oriented | Speedup |
|---|---|---|---|
| countWarriors (100) | 10,874,045 ops/s | 19,314,177 ops/s | 78% |
| countWarriors (1000) | 1,147,493 ops/s | 1,842,812 ops/s | 61% |
| countWarriors (10'000) | 102,630 ops/s | 185,486 ops/s | 81% |
By changing the way we look at the problem, we were able to gain a large speedup. Keep in mind that in our example the ant class is relatively small, therefore that data will most likely stay in one of the CPU caches and the difference between the two approaches is not as exaggerated (according to the latency table, accessing memory from the cache is 30-100 times faster).
Even though the examples above are written in the free spirited everything is public approach, the data oriented design does not prohibit you from using the enterprise control freak approach. You can still make every field private and final, provide getters and setters and implement a few interfaces if you are really into that.
You may even realize that all of that enterprise cruft is not really necessary, who knows? But the most important takeaway from this example is to stop thinking about ants in an one by one fashion and rather think about them as a group. After all, where have you seen only one ant?
Where there’s one, there’s more than one.
Mike Acton
But, wait! Why is an object oriented approach so popular if it performs so badly?
Workload is often IO based (at least on server backends), which is roughly 1000 times slower than the memory access. If you are writing a lot of data to the hard drive, improvements made in the memory layout might not drastically improve your throughput.
The performance requirements for most enterprise software are embarrassingly low and any ol’ code will do. This is also known as the “but, the customer is not going to pay for that” syndrome.
The ideas in the industry are moving slowly and the software cultists refuse to change. A mere 20 years ago memory latency wasn’t a big problem and the programming best practices haven’t caught up with the changes in the hardware.
Most languages support this type of programming and it’s easy to wrap your mind around the notion of objects.
Data oriented way of programming has its own set of problems.
Problems: say we would like to find out how many red ants older than 1 ant year are living in the colony. With the object oriented approach, that is pretty simple:
long numOfChosenAnts = 0;
for (Ant ant : antColony) {
if (ant.age > 1 && "red".equals(ant.color)) {
numOfChosenAnts++;
}
}
With the data oriented approach, it gets slightly more annoying as we have to be careful how we iterate over our arrays (we have to use the element located at the same index):
long numOfChosenAnts = 0;
for (int i = 0; i < antColony.size; i++) {
int age = antColony.ages[i];
String color = antColony.colors[i];
if (age > 1 && "red".equals(color)) {
numOfChosenAnts++;
}
}
Now imagine someone would like to sort all the ants in the colony based on their name and then do something with the sorted data (e.g., count all the red ants of the first 10% of the sorted data. Ants might have weird business rules like that, don’t judge them). In an object oriented way, you simply use the sort function from the standard library. In the data oriented way, you have to sort an array of names, but at the same time also sort all the other arrays based on how the indices of the name array moved (assuming you care which color, age and warrior flag goes with the ant’s name) 6.
This is exactly the type of problem that should be solved via the features of our programming languages, since writing these custom sorting functions is very tedious. What if a programming language would provide us with a structure that would act like an array of structs, but internally it would really behave like a struct of arrays? We could program in the typical object oriented way that is convenient for humans, while still enjoying in great performance due to playing nice with the hardware.
So far, the only programming language I know of that supports this type of crazy data transformations is JAI, but unfortunately it’s still in closed beta and not available for the general public to use. Why on earth is this functionality not baked in our “modern” programming languages is something to ponder about.
Best practices
If you ever stepped into an enterprise shop and snooped around in their codebase, what you most likely saw was a giant pile of classes with numerous member fields and interfaces sprinkled on top. Most of the software is still written in that way, because it’s relatively easy to wrap your mind around that type of programming and due to influences from the past. Large codebases are also a giant molasses 7 and those who are working on them will naturally gravitate towards the familiar style that they see every day.
Changing the ideas on how to approach problems usually takes more effort than parroting: “Use const and the compiler will optimize that away!” Nobody knows what the compiler will do, if nobody checked what the compiler did.
Compiler is a tool, not a magic wand!
Mike Acton
The reason why I wrote this article is because a lot of programmers believe that you have to be a genius or know arcane compiler tricks in order to write code that performs well. A simple reasoning about the data that flows in your system will get you there for the most part 8. In a complex program it’s not always easy to do that, but that is also something that anyone can learn if they are willing to spend some time tinkering with these concepts.
If you would like to learn more about this topic, make sure to read the Data-Oriented Design book and the rest of the links that are listed in the notes section.
Discussion
Translations
Additional reading material
On reducing the memory footprint in programs: The Lost Art of Structure Packing
An article describing the problems of object-oriented programming: Data-Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP)
Notes
From the Data Oriented Design - Mike Acton (2014) talk in which he pointed out that in the analyzed snippet only 10% of the problem is what the compiler can optimize in theory and the 90% of the problem is what the compiler can’t possibly optimize.
If you would like to learn more about the memory, you may want to read What every programmer should know about memory. If you are curious about the number of cycles that a certain CPU instruction burns, feel free to dive into the CPU instruction tables. ↩︎
From the Pitfalls of object oriented programming - Tony Albrecht (2009), slide 17. You can also check out his video (2017) on the same topic. ↩︎
Latency table is taken from the Systems Performance: Enterprise and the cloud (2nd Edition - 2020). ↩︎
Memory is not always the bottleneck. If you are writing or reading a lot of data, the bottleneck will most likely be your hard drive. If you are rendering a lot of things on the screen, the bottleneck might be your GPU. ↩︎
If you allocate all the instances at the same time one after another, chances are, they will also be located one after another in the heap which will speed up your iterations. In general, it’s best to preallocate all your data at startup to avoid having your instances spread out through your entire heap, although if you are using a managed language it’s hard to speculate what the garbage collectors will do in the background. For example, the JVM developers claim that allocating small objects and deallocating them right after might perform better than keeping a pool of preallocated objects due to the way the generational garbage collectors work. ↩︎
You could also copy the name array, sort it and find the relevant name in the original unsorted name array to get back the index of the relevant element. Once you have the element array index you can do whatever you want, but it’s tedious to make this kind of lookups. If your arrays are big this approach is also quite slow. Know your data!
Another problem that was not mentioned above is inserting or deleting elements from the middle of the array. When you add or remove the element from the middle of the array that usually involves copying the entire modified array to a new location in memory. Copying the data is slow and if you are not careful with how you copy the data, you could also run out of memory.
If the order of the elements in the arrays do not matter, you can also swap the deleted element with the last element of the array and decrease the internal counter that counts the number of active elements in your group. When iterating over the elements in this situation, you will essentially only iterate through the active part of the group.
Linked list is not a viable solution for this problem, since your data is not allocated in contiguous chunks which makes the iteration very slow (poor cache utilization). ↩︎
See also On navigating a large codebase. ↩︎
That doesn’t mean the code will be always simple and easy to understand - the code for efficient matrix multiplication is quite hairy. ↩︎